|
Questi appunti sono basati sui libri "Computer
Networks" di A. Tanenbaum, terza edizione, ed. Prentice-Hall,
e "Java Network Programming" di Merlin Hughes et al.,
Mannig Publications Co, Greenwich CT, adottati quali libri di
testo del corso.
Essi rispecchiano piuttosto fedelmente il livello di dettaglio
che viene seguito durante le lezioni, e costituiscono un ausilio
didattico allo studio.
Tuttavia, è importante chiarire che gli appunti non vanno
intesi come sostitutivi né dei libri di testo né
della frequenza alle lezioni, che rimangono fattori importanti
per una buona preparazione dell'esame.
La realizzazione di questi appunti è stata resa possibile
dalla collaborazione di alcuni studenti, che hanno avuto la pazienza
di convertire in forma elettronica il contenuto testuale dei manoscritti
da me preparati per il corso. La realizzazione delle figure, la
formattazione e la rifinitura del testo sono opera mia.
1) Il World Wide Web |
Il World Wide Web
(detto anche Web,
WWW o W3)
è nato al Cern nel 1989 per consentire una agevole cooperazione
fra i gruppi di ricerca di fisica sparsi nel mondo.
E' un'architettura software volta a fornire l'accesso e la navigazione
a un enorme insieme di documenti collegati fra loro e sparsi su
milioni di elaboratori.
Tale insieme di documenti forma un ipertesto (hypertext), cioè un testo che viene percorso in modo non lineare. Il concetto di ipertesto risale alla fine degli anni '40, e si deve a vari scienziati:
Il Web ha diverse caratteristiche che hanno contribuito al suo enorme successo:
I documenti che costituiscono l'ipertesto gestito dal Web sono detti pagine web, e possono contenere, oltre a normale testo formattato, anche:
L'utilizzo del Web è semplicissimo:
Si noti che la nuova pagina può provenire da qualunque
parte del pianeta.
1.1) Architettura client-server del Web |
Il Web è una architettura software
di tipo client-server,
nella quale sono previste due tipologie di componenti software:
il client e il server,
ciascuno avente compiti ben definiti.
1.1.1) Client |
Il client (o user
agent) è lo strumento a disposizione dell'utente
che gli permette l'accesso e la navigazione nell'ipertesto del
Web.
Esso ha varie competenze:
I client vengono comunemente chiamati browser (sfogliatori). Gli esempi più noti sono:
In generale è troppo complicato e costoso (sarebbero necessari
aggiornamenti troppo frequenti) sviluppare un browser che sappia
gestire direttamente tutti i tipi di informazioni presenti sul
Web, poiché essi sono in continuo e rapido aumento.
Per questa ragione, di norma i browser gestiscono direttamente solo alcune tipologie di informazioni, quali:
Viceversa, di norma gli altri tipi di informazioni vengono gestiti in uno (o entrambi) dei seguenti modi:
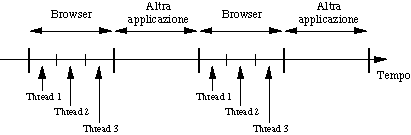
Una importante caratteristica di tutti i browser moderni è
di essere multithreaded,
cioè di consentire che, quando la cpu è sotto il
loro controllo, si alternino fra loro multipli thread
di controllo, cioè flussi di elaborazione
concorrenti. Spesso si usa come sinonimo di thread il termine
lightweight process.
Ad esempio, nel caso di un sistema operativo (S.O.) che offre
il multitasking, si può avere una situazione come quella
seguente.
Un thread, a differenza di un vero processo, è un contesto
di esecuzione il cui spazio di indirizzamento viene ricavato all'interno
di quello del processo che lo ha generato.
1.1.2) Server |
Il server è tipicamente un processo in esecuzione su un elaboratore. Esso, di norma, è sempre in esecuzione (tranne che in situazioni eccezionali) ed ha delle incombenze molto semplici, almeno in linea di principio. Infatti deve:
Nonostante la apparente semplicità di tale compito, la realizzazione di un server non è banale, perché:
Il secondo requisito in particolare implica una qualche forma
di concorrenza nel lavoro del server. Essa si può ottenere
in vari modi, anche in funzione delle caratteristiche del sistema
operativo sottostante. Le due tecniche più diffuse sono
descritte nel seguito.
Clonazione del server
L'idea è semplice:
Le varie copie del server vivono in spazi di indirizzamento separati,
e il loro avvicendamento nell'uso della CPU è governato
dal sistema operativo.
Questo è un metodo tipico di S.O. multitasking quali UNIX,
e si ottiene con l'uso della fork().
Vantaggi:
Svantaggi
Server multithreaded
Esiste una sola copia del server, che però è progettato per essere in grado di generare thread multipli:
Questo metodo richiede che il S.O. offra librerie di supporto
al multithreading, che ormai sono presenti in tutti i S.O. moderni
(UNIX, Windows 95 e NT, MacOS, Linux) per cui di fatto è
universalmente applicabile.
Vantaggi:
fork() (anche 30 volte sotto UNIX), quindi
in generale è più efficiente per gestire operazioni
veloci come l'esaudire la richiesta del client.
Svantaggi:
1.2) Standard utilizzati nel Web |
Ci sono tre standard principali che, nel loro insieme, costituiscono l'architettura software del Web:
1.2.1) URL |
Una URL costituisce un riferimento a una qualunque
risorsa accessibile nel Web.
Tale risorsa ovviamente risiede da qualche parte, ed è
in generale possibile accedervi in vari modi.
Dunque, una URL deve essere in grado di indicare:
Per queste ragioni, una URL è fatta di 3 parti, che specificano:
Un tipico esempio di una URL è:
http://somewhere.net/products/index.html
nella quale:
http:// | è il metodo di accesso |
somewhere.net | è il nome dell'host |
/products/index.html | è l'identità della risorsa |
Metodo di accesso
Indica il modo di accedere alla risorsa, cioè che tipo
di protocollo bisogna usare per colloquiare col server che controlla
la risorsa.
I metodi di accesso più comuni sono:
| http | protocollo nativo del Web |
| ftp | file transfer protocol |
| news | protocollo per l'accesso ai gruppi di discussione |
| gopher | vecchio protocollo per il reperimento di informazioni; concettualmente simile al Web, gestisce solo testo |
| mailto | usato per spedire posta |
| telnet | protocollo di terminale virtuale, per effettuare login remoti |
| file | accesso a documenti locali |
Il Web nasce con l'idea di inglobare gli altri protocolli di accesso
alle informazioni, per costituire un ambiente unificato che soddisfa
tutte le esigenze.
Quando il client effettua la richiesta di una risorsa, usa nel
dialogo col server il protocollo specificato dal metodo d'accesso.
Se non è in grado di farlo, affida il compito a una applicazione
helper esterna (questo è tipicamente il
caso del protocollo telnet: il client lancia un emulatore di terminale
passandogli il nome dell'host).
Dall'altra parte risponde il server di competenza, che può essere:
Nome dell'host
Può essere l'indirizzo IP
numerico o, più comunemente, il nome
DNS dell'host a cui si vuole chiedere la risorsa.
Dopo il nome dell'host può essere incluso anche un numero
di port. Se non c'è, si intende il port
80 (che è il default). Ad esempio:
http://somewhere.net:8000/products/index.html
In questo modo si possono avere, sullo stesso host, diversi server
Web in ascolto su diverse porte.
Identità della risorsa
Consiste, nella sua forma più completa, della specifica
del nome di un file e del cammino che porta al direttorio in cui
si trova.
Ad esempio, la URL:
http://somewhere.net/products/toasters/index.html
specifica il file index.html contenuto nel direttorio
toasters, a sua volta contenuto nel direttorio products
il quale si trova nel direttorio radice dell'host somewhere.net.
Si noti che:
Esistono alcune regole per il completamento di URL non interamente specificate:
Infine, una convenzione usata spesso è la seguente. A fronte
di una URL del tipo:
http://somewhere.net/~username/
il server restituisce il file welcome.html situato
nel direttorio public_html situato nel direttorio
principale (home directory)
dell'utente username.
Questo meccanismo consente agli utenti, che di norma hanno libero
accesso al proprio home directory, di mantenere facilmente proprie
pagine Web.
1.2.2) Linguaggio HTML |
Il linguaggio per la formattazione di testo
HTML è una specializzazione del linguaggio SGML
(Standard Generalized Markup Language)
definito nello standard ISO 8879.
HTML è specializzato nel senso che è stato progettato
appositamente per un utilizzo nell'ambito del Web.
Un markup language si
chiama così perché i comandi (tag)
per la formattazione sono inseriti in modo esplicito nel testo,
a differenza di quanto avviene in un word processor WYSIWYG
(What You See Is What You Get),
nel quale il testo appare visivamente dotato dei suoi formati,
come fosse stampato. TROFF e TeX sono altri markup language, mentre
ad esempio Microsoft Word è WYSIWYG.
Per esempio in HTML il testo:
...questo è <B>grassetto</B>
e questo no...
indica che la parola grassetto deve essere visualizzata
in grassetto (bold).
Quindi il testo in questione dovrà apparire come segue:
Il ruolo di HTML è quindi quello di definire il modo in
cui deve essere visualizzata una pagina Web (detta anche pagina
HTML), che tipicamente è un documento di
tipo testuale contenente opportuni tag di HTML.
Il client, quando riceve una pagina compie le seguenti operazioni:
Nella formattazione si ignorano:
I tag HTML possono essere divisi in due categorie:
Il linguaggio HTML è in costante evoluzione, si è
passati dalla versione 1.0 alla 2.0 (rfc 1866), poi alla 3.0 e
ora alla 3.2.
E' in corso una attività di standardizzazione della versione
3, che cerca di mediare le proposte, spesso incompatibili, che
sono portate avanti da diverse organizzazioni (quali Netscape
e Microsoft) le quali spingono perché proprie estensioni
(ad esempio i frame di
Netscape e gli style sheet
di Microsoft) divengano parte dello standard.
In genere i tag hanno la forma:
<direttiva> ... </direttiva>
e possono contenere parametri:
<direttiva parametro1="valore"...>
... </direttiva>
Struttura di un documento HTML
Una pagina HTML ha questa struttura:
|
Il ruolo di questi marcatori è il seguente:
| HTML | Inizio e fine del documento |
| HEAD | Questa parte non viene mostrata e contiene metainformazioni sul documento (creatore, data di "scadenza", e se c'è, il titolo) |
| TITLE | Il titolo del documento: appare come titolo della finestra che lo contiene |
| BODY | Il suo contenuto viene visualizzato nella finestra |
Tag per la formattazione
Alcuni dei tag esistenti per la formattazione del testo sono i
seguenti:
<B>...</B> | Grassetto (bold) |
<I>...</I> | Corsivo (italic) |
<Hx>...</Hx> | Intestazione (heading) di livello x (da 1 a 6) |
<PRE>...</PRE> |
Testo visualizzato esattamente come è scritto (preformatted), con spazi multipli, caratteri di fine linea, ecc. |
Ci sono moltissimi altri tag per la formattazione, coi quali si possono specificare:
<TABLE>);
<HR>,<BR>,<P>);
<FRAMESET>,
<FRAME>).
Tag per altre finalità
Questi sono i tag che forniscono al Web la sua grande versatilità.
Anch'essi sono in continua evoluzione, permettendo di includere
sempre nuove funzionalità.
I tag di questo tipo più usati sono quelli per la inclusione
di immagini in-line (visualizzate
direttamente all'interno della pagina) e per la gestione degli
hyperlink.
Il tag per la inclusione di immagini ha la seguente forma:
<IMG SRC="url"> oppure
<IMG SRC="url" ALT="testo...">
Questo tag fa apparire l'immagine di cui alla URL. L'immagine
(se il client è configurato per farlo) viene richiesta
automaticamente e quando è disponibile viene mostrata.
Altrimenti, al suo posto appare una piccola icona, sulla quale
bisogna fare click se si vuole vedere la relativa immagine (che
solo allora verrà richiesta), seguita dal testo specificato
nel parametro ALT.
Altri parametri del tag <IMG> servono a:
WIDTH, HEIGHT);
ALIGN);
ISMAP).
Tag per la gestione degli hyperlink
Costituiscono il fondamento funzionale su cui è basato
il Web, perché è per mezzo di questi che si realizzano
le funzioni ipertestuali.
Il tag è uno solo (con alcune varianti) e viene chiamato
anchor:
<A> .....</A>
La sua forma standard è:
...<A HREF="url">testo visibile</A>...
Nella pagina la stringa testo visibile appare sottolineata
e, di norma, di colore blu:
Quando l'utente fa click su un'ancora (ossia sul testo visibile
della stessa) il client provvede a richiedere il documento di
cui alla URL, lo riceve, lo formatta e lo mostra nella finestra
al posto di quello precedente.
1.2.3) Il protocollo HTTP |
Il protocollo HTTP sovraintende al dialogo
fra un client e un server web, ed è il linguaggio nativo
del Web.
HTTP non è ancora uno standard ufficiale. Infatti, HTTP
1.0 (rfc 1945) è informational,
mentre HTTP 1.1 (rfc 2068) è ancora in fase di proposta;
parleremo di quest'ultimo più avanti.
HTTP è un protocollo ASCII,
cioè i messaggi scambiati fra client e server sono costituiti
da sequenze di caratteri ASCII (e questo, come vedremo, è
un problema se è necessaria la riservatezza delle comunicazioni).
In questo contesto per messaggio
si intende la richiesta del cliente oppure la risposta del server,
intesa come informazione di controllo; viceversa, i dati della
URL richiesta che vengono restituiti dal server non sono necessariamente
ASCII (esempi di dati binari: immagini, filmati, suoni, codice
eseguibile).
Il protocollo prevede che ogni singola interazione fra client e server si svolga secondo il seguente schema:
Dunque, il protocollo è di tipo stateless,
cioè non è previsto il concetto di sessione
all'interno della quale ci si ricorda dello stato dell'interazione
fra client e server. Ogni singola interazione è storia
a se ed è del tutto indipendente dalle altre.
La richiesta del client
Quando un client effettua una richiesta invia diverse informazioni:
I metodi definiti in HTTP sono:
| GET | Richiesta di ricevere un oggetto dal server |
| HEAD | Richiesta di ricevere la sola parte head di una pagina html |
| PUT | Richiesta di mandare un oggetto al server |
| POST | Richiesta di appendere sul server un oggetto a un altro (vedremo che si usa molto) |
| DELETE | Richiesta di cancellare sul server un oggetto |
| LINK e UNLINK | Richieste di stabilire o eliminare collegamenti fra oggetti del server |
In proposito, si noti che:
Ad esempio, supponiamo che nel file HTML visualizzato sul client
vi sia un'ancora:
<A HREF="http://somewhere.net/products/toasters/index.html">
..... </A>
e che l'utente attivi tale link. A tal punto il client:
Essa è costituita da un insieme di comandi (uno per ogni
linea di testo) terminati con una linea vuota:
GET /products/toasters/index.html HTTP/1.0
| Metodo, URL e versione protocollo |
User-agent: Mozilla/3.0 | Tipo del client |
Host: 160.10.5.43 | Indirizzo IP del client |
Accept: text/html | Client accetta pagine HTML |
Accept: image/gif | Client accetta immagini |
Accept: application/octet-stream
| Client accetta file binari qualunque |
If-modified-since: data e ora |
Inviare il documento solo se è più recente della data specificata |
La risposta del server
La risposta del server è articolata in più parti,
perché c'è un problema di fondo: come farà
il client a sapere in che modo dovrà gestire le informazioni
che gli arriveranno?
Ovviamente, non si può mostrare sotto forma di testo un'immagine
o un file sonoro! Dunque, si deve informare il client sulla natura
dei dati che gli arriveranno prima di iniziare a spedirglieli.
Per questo motivo la risposta consiste di 3 parti:
La riga di stato, a sua volta, consiste di tre parti:
Tipici codici di stato sono:
| Tutto ok | 200 |
OK |
| Documento spostato | 301
| Moved permanently |
| Richiesta di autenticazione | 401
| Unauthorized |
| Richiesta di pagamento | 402
| Payment required |
| Accesso vietato | 403
| Forbidden |
| Documento non esistente | 404
| Not found |
| Errore nel server | 500
| Server error |
Dunque, ad esempio, si potrà avere
HTTP/1.0 200 OK
Le metainformazioni dicono al client ciò che deve sapere
per poter gestire correttamente i dati che riceverà.
Sono elencate in linee di testo successive alla riga di stato
e terminano con una linea vuota.
Tipiche metainformazioni sono:
Server: ... | Identifica il tipo di server |
Date: ... | Data e ora della risposta |
Content-type: ... | Tipo dell'oggetto inviato |
Content-length: ... | Numero di byte dell'oggetto inviato |
Content-language: ... | Linguaggio delle informazioni |
Last-modified: ... | Data e ora di ultima modifica |
Content-encoding: ... | Tipo di decodifica per ottenere il content |
Il Content-type si specifica usando lo standard MIME
(Multipurpose Internet Mail Exchange),
nato originariamente per estendere la funzionalità della
posta elettronica.
Un tipo MIME è specificato da una coppia
MIME type/MIME subtype
Vari tipi MIME sono definiti, e molti altri continuano ad aggiungersi.
I più comuni sono:
text/plain | .txt, .java
| testo |
text/html | .html, .htm
| pagine html |
image/gif | .gif
| immagini gif |
image/jpeg | .jpeg, .jpg
| immagini jpeg |
audio/basic | .au
| suoni |
video/mpeg | .mpeg
| filmati |
application/octet-stream | .class, .cla, .exe
| programmi eseguibili |
application/postscript | .ps
| documenti Postscript |
x-world/x-vrml | .vrml, .wrl
| scenari 3D |
Il server viene configurato associando alle varie estensioni i
corrispondenti tipi MIME. Quando gli viene chiesto un file, deduce
dall'estensione e dalla propria configurazione il tipo MIME che
deve comunicare al client.
Se la corrispondenza non è nota, si usa quella di default
(tipicamente text/html), il che può causare errori in fase
di visualizzazione.
Anche la configurazione del client (in merito alle applicazioni
helper) si fa sulla base dei tipi MIME.
Tornando al nostro esempio, una richiesta del client quale:
GET /products/toasters/index.html HTTP/1.0
User-agent: Mozilla/3.0
ecc.
riceverà come risposta dal server (supponendo che non ci
siano errori) le metainformazioni, poi una riga vuota e quindi
il contenuto del documento (in questo caso una pagina HTML costituita
di 6528 byte):
HTTP/1.0 200 OK
Server: NCSA/1.4
Date: Tue, july 4, 1996 19:17:05 GMT
Content-type: text/html
Content-length: 6528
Content-language: en
Last-modified: Mon, july 3, 1996 15:05:35 GMT
<----- notare la riga vuota
<HTML>
<HEAD>
...
<TITLE>...</TITLE>
...
</HEAD >
<BODY>
...
</BODY>
</HTML>