1.3) Estensioni del Web |
Al crescente successo del Web si è
accompagnato un continuo lavoro per ampliarne le possibilità
di utilizzo e le funzionalità offerte agli utenti.
In particolare, si è presto sentita l'esigenza di fornire
un supporto a una qualche forma di interattività superiore
a quella offerta dalla navigazione attraverso gli hyperlink, ad
esempio per consentire agli utenti di consultare una base di dati
remota via Web.
Le principali estensioni del Web da questo punto di vista sono:
1.3.1) Estensione per mezzo delle form |
Finora abbiamo sempre implicitamente considerato
una URL come un riferimento ad un oggetto passivo, quale ad esempio
una pagina HTML o un'immagine.
Ciò non è vero in generale, infatti una URL può
fare riferimento a un qualunque tipo di oggetto, e in particolare
anche a un file eseguibile.
Proprio grazie a queste generalità del meccanismo di indirizzamento
URL si è definita una potente estensione Web, che lo mette
in grado di integrare praticamente ogni tipo di applicazione esterna.
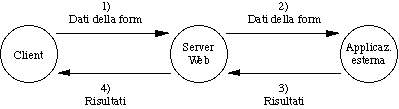
L'estensione di funzionalità di cui stiamo parlando è costituita da due componenti:
Idealmente, la situazione è questa:
Ad esempio, supponiamo di avere questo scenario (che è anche il più tipico):
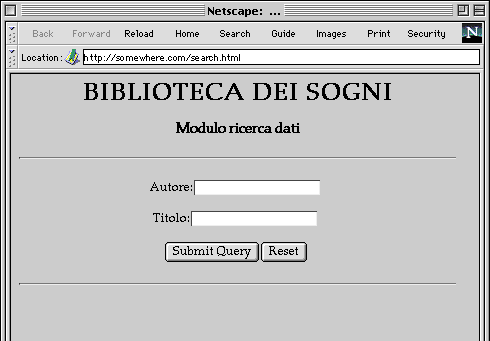
Immaginiamo che si voglia presentare all'utente un modulo di ricerca
in biblioteca di questo tipo (in una pagina HTML):
Esistono degli appositi tag di HTML destinati a creare simili moduli. è possibile includere:
Nel nostro caso, il codice HTML che genera il modulo sopra visto
è il seguente:
<HTML> <HEAD><TITLE> ... </TITLE></HEAD> </BODY> <CENTER> <H1>BIBLIOTECA DEI SOGNI</H1> <H3>Modulo ricerca dati</H3> <HR> <FORM ACTION="http://somewhere.com/scripts/biblio.cgi"> Autore:<INPUT TYPE="text" NAME="autore" MAXLENGTH="64"> <P> Titolo:<INPUT TYPE="text" NAME="titolo" MAXLENGTH="64"> <P> <INPUT TYPE="submit"><INPUT TYPE="reset"> </FORM> <HR> </BODY> </HTML> |
Il tag <FORM ... > ha un parametro ACTION
che specifica l'oggetto (ossia il programma) a cui il server dovrà
consegnare i dati immessi dall'utente. In questo caso, vanno consegnati
a un programma il cui nome biblio.cgi (vedremo poi
il perché di questa estensione).
I tag <INPUT ... > definiscono le parti della
form che gestiscono l'interazione con l'utente. In questo caso
abbiamo:
Quando l'utente preme il bottone "Submit Query" il client
provvede a inviare i dati al server, assieme all'indicazione dell'URL
alla quale consegnarli.
I dati vengono inviati come coppie:
NomeDelCampo1=ValoreDelCampo1&NomeDelCampo2=ValoreDelCampo2
ecc.dove:
NomeDelCampo viene dal parametro NAME;
ValoreDelCampo è la stringa immessa dall'utente
in quel campo;
& e
sono opportunamente codificate, se ci sono spazi e caratteri speciali.
La forma specifica del messaggio inviato dal client dipende anche
da un altro parametro del tag FORM: oltre a ACTION=...
c'è anche METHOD=... , che può essere:
GET, assunto implicitamente (come nel nostro
esempio);
POST, che deve essere indicato in modo esplicito
(questo è praticamente l'unico ambito nel quale è
ammesso l'uso di tale comando).
Dunque, possiamo avere:
<FORM ACTION=".....">
<FORM ACTION="....." METHOD="get">
<FORM ACTION="....." METHOD="post">
Nel primo e nel secondo caso, la richiesta inviata dal client
consiste nella specifica della URL alla quale vengono "appesi"
i dati richiesti (con un punto di domanda):
GET /scripts/biblio.cgi?titolo=congo&autore=crichton&submit=submit HTTP/1.0
User-agent: ...
Accept: ...
...
<----- riga vuota
Nel caso del metodo POST, che in questo contesto
è molto diffuso, i dati vengono rinviati nel corpo del
messaggio:
POST /scripts/biblio.cgi HTTP/1.0
User-agent: ...
Accept: ...
...
Content-type: application/x-www-form-urlencoded
Content-length: 42
<----- riga vuota
titolo=congo&autore=crichton&submit=submit <----- dati della form
Il primo metodo è molto semplice, ma impone un limite al
numero di caratteri che possono essere spediti. Il secondo invece
non ha alcun limite, ed è da preferire perché probabilmente
il primo verrà prima o poi abbandonato.
Quando il server riceve la richiesta, da questa è in grado di capire:
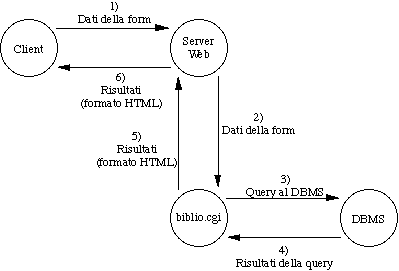
Nel nostro esempio (che è un caso tipico) il programma
biblio.cgi avrà l'incarico di:
1.3.2) Common Gateway Interface |
Il programma biblio.cgi del nostro
esempio precedente fa da gateway
fra il server Web e l'applicazione esterna che si vuole utilizzare,
nel senso che oltre che metterli in comunicazione è anche
incaricato di operare le opportune trasformazioni dei dati che
gli giungono da entrambe le direzioni.
Da ciò deriva il nome CGI
(Common Gateway Interface)
per lo standard che definisce alcuni aspetti della comunicazione
fra il server Web e il programma gateway, e l'uso dell'estensione
.cgi per tali programmi.
Un programma CGI può essere scritto in qualunque linguaggio:
Si tenga presente che lo standard illustrato qui è di fatto
relativo alla piattaforma UNIX. Per altre piattaforme i meccanismi
di comunicazione previsti dalla relativa Common Gateway Interface
possono essere differenti, fermo restando che le informazioni
passate sono essenzialmente le stesse.
Per la comunicazione dal server Web al programma CGI si utilizzano:
POST:
i dati della form vengono inviati mediante pipe).
Molte variabili d'ambiente vengono impostate dal server prima
di lanciare il programma CGI; le principali sono:
| QUERY_STRING | La lista di coppie campo=valore (usata con il metodo GET)
|
| PATH_INFO | Informazioni aggiuntive messe dopo l'URL (usate ad esempio con le clickable map) |
| CONTENT_TYPE | Usata con il metodo POST, indica il tipo MIME delle informazioni che arriveranno (application/x-www-form-urlencoded);
|
| CONTENT_LENGTH | Usata con il metodo POST, indica quanti byte arriveranno sullo standard input del programma CGI
|
In più ci sono altre variabili per sapere chi è
il server, chi è il client, per la autenticazione, ecc.
Le comunicazioni dal programma CGI al server Web avvengono grazie
al fatto che il programma CGI invia l'output sul suo standard
output, che viene collegato tramite pipe allo standard input del
server Web.
Ci si aspetta che il programma CGI possa fare solo due cose:
L'output del programma CGI deve iniziare con un breve header contenente
delle metainformazioni, che istruisce il server su cosa fare.
Poi una riga vuota, quindi l'eventuale pagina HTML.
Le metainformazioni che il server prende in considerazione (tutte
le altre vengono passate al client) sono:
| Metainformazione | Valori | Significato |
| Content-type: | Tipo/Sottotipo MIME | Tipo dei dati che seguono |
| Location: | URL | File da restituire al client |
| Status: | OK, Error | Esito dell'elaborazione |
Ad esempio, supponendo di usare un linguaggio di programmazione
nel quale sia definita una ipotetica procedura println(String
s) che scrive una linea di testo sullo standard output,
un programma CGI che genera al volo una semplice pagina HTML potrà
contenere al suo interno una sequenza di istruzioni quale:
println("Status: 200 OK");
println("Content-type: text/html");
println(""); //linea vuota che delimita la fine delle metainformazioni
println("<HTML>");
println("<HEAD>");
...
println("</HEAD>");
println("<BODY>");
...
println("</BODY>");
println("</HTML>");
Viceversa, se il programma CGI vuole effettuare una URL redirection
il codice eseguito potrà essere:
println("Status: 200 OK");
println("Location: /docs/index.html");
println(""); //linea vuota che delimita la fine delle metainformazioni
Per gli altri sistemi operativi i meccanismi di comunicazione possono essere diversi:
Dunque, la tipica catena di eventi è la seguente:
Ulteriori usi del meccanismo CGI si presentano in relazione a:
Server side image map
L'idea è di avere sul client un'immagine sensibile al click
del mouse che possa fare da "ponte" verso nuove pagine
HTML scelte sulla base del punto dell'immagine sul quale si preme
il pulsante.
Sul server sono necessari:
Il funzionamento è il seguente:
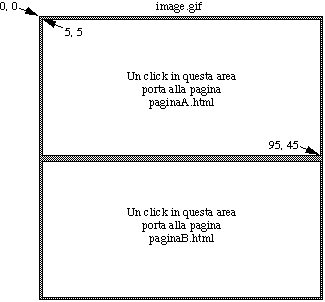
Supponiamo che:
rect /paginaA.html 5,5,95,45
rect /paginaB.html 5,55,95,95
Tali linee impongono la seguente struttura (invisibile) sull'immagine
image.gif:
Nella pagina di partenza l'ancora che contiene l'immagine sensibile
è del tipo:
<A HREF="image.cgi$image.map"><IMG SRC="image.gif"
ISMAP></A>
Quando l'utente fa click, ad esempio, nel punto 50, 20 dell'immagine
(l'origine è in alto a sinistra), il client invia la richiesta:
GET image.cgi$image.map?50,20 HTTP/1.0
Il server lancia il programma image.cgi, che riceve
il nome del file di mappa e le coordinate, e quindi restituisce
(tramite URL redirection) il file paginaA.html da mostrare al
client.
Client Side Image Map
Recentemente è stato introdotto un nuovo meccanismo per
ottenere un comportamento analogo senza bisogno di interagire
col server.
Il client fa tutto da solo, poiché trova le informazioni
necessarie direttamente nella pagina HTML.
In sostanza, si definisce la mappa in HTML e si dice al client
di usare direttamente quella. Il caso precedente diventa:
<IMG SRC="image.gif" USEMAP="#localmap"> <MAP NAME="localmap"> <AREA COORDS="5,5,95,45" HREF="paginaA.html"> <AREA COORDS="5,55,95,95" HREF="paginaB.html"> </MAP>
Facendo click su una delle due aree, il client invia direttamente
la richiesta della pagina A o B.
Per garantire la compatibilità con i client più
vecchi, che non gestiscono il parametro USEMAP, si
possono far coesistere le due possibilità:
<A HREF="image.cgi$image.map"><IMG SRC="image.gif" ISMAP USEMAP="#localmap"></A> <MAP NAME="localmap"> <AREA COORDS="5,5,95,45" HREF="paginaA.html"> <AREA COORDS="5,55,95,95" HREF="paginaB.html"> </MAP>
Motori di ricerca
Esistono dei siti che offrono funzioni di ricerca di informazioni sull'intera rete Internet. In generale essi sono costituiti di 3 componenti:
1.3.3) Linguaggio JavaScript (già LiveScript) |
E' una proposta di Netscape. Consiste nella
definizione di un completo linguaggio a oggetti, con sintassi
analoga a Java, con il quale si possono definire delle computazioni
direttamente nel testo della pagina HTML. Tali computazioni vengono
poi eseguite dal browser.
Ad esempio, si può usare JavaScript per controllare che
i vari campi di una form siano riempiti in modo sintatticamente
corretto prima di inviare i dati al server.
Nell'esempio che segue, il bottone "submit" chiama una
routine JavaScript di controllo del campo cognome. Se esso è
vuoto si avvisa l'utente dell'errore, altrimenti si invia la form.
<HTML>
<HEAD>
<SCRIPT LANGUAGE="LiveScript">
function checkForm (form){
if (form.cognome.value == "") {
alert("Errore: il campo \"Cognome\" non puo\' essere vuoto");
form.cognome.focus();
form.cognome.select();
} else {
form.submit();
}
}
</SCRIPT>
</HEAD>
<BODY>
<CENTER>
<FORM>
Cognome:<INPUT NAME="cognome" VALUE="">
<P>
<INPUT TYPE="button" VALUE="Submit"
onClick="checkForm (this.form);"
>
<INPUT TYPE="reset">
</FORM>
</CENTER>
</BODY>
</HTML>
|
L'effetto di un errore di immissione, dal punto di vista dell'utente,
è il seguente:
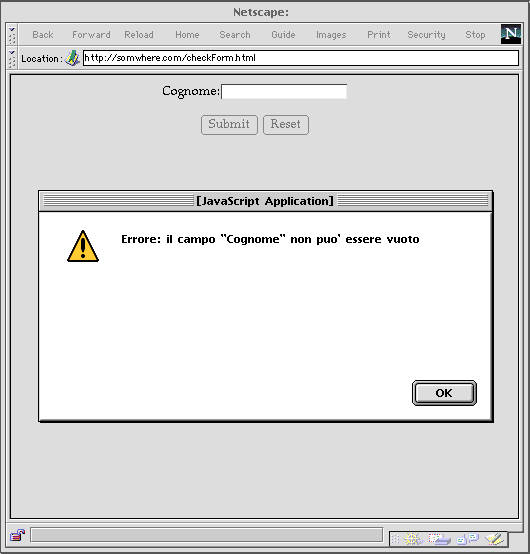
Si noti che all'utente il bottone di invio sembra di tipo Submit,
ma in realtà è di tipo Button, altrimenti la pressione
su di esso causerebbe comunque l'invio dei dati della form.
Il linguaggio consente:
Gli oggetti predefiniti sono organizzati in una gerarchia i cui principali elementi sono:
Ogni singolo oggetto contiene una istanza di ciascun tipo di oggetto
in esso contenuto: ad esempio, un oggetto Form contiene le istanze
di tutti i campi immissione dati, bottoni ecc. che sono inclusi
nella form stessa.
1.3.4) Linguaggio Java |
Anche disponendo delle form e dei programmi
CGI, ciò che rimane impossibile è avere una rapida
interazione con la pagina Web.
Inoltre, la vertiginosa apparizione di nuove tipologie di informazioni
da gestire e nuovi tipi di servizi da offrire rende problematico
l'aggiornamento dei client: troppo spesso si devono ampliare le
loro funzionalità o si deve ricorrere a programmi helper
e plug-in.
La prima risposta a entrambi questi problemi è venuta da
una proposta della Sun che ha immediatamente suscitato un enorme
interesse a livello mondiale: il linguaggio Java e il relativo
interprete.
Originariamente (nei primi anni '90) il linguaggio si chiamava OAK ed era destinato alla produzione di software per elettrodomestici (orientati all'informazione) connessi in rete. Era progettato per:
Successivamente il progetto fu riorientato verso il Web, il linguaggio
ha preso il nome di Java ed ha conosciuto un enorme successo.
L'idea di fondo è molto semplice:
In questo modo si ottiene di fatto la possibilità di estendere senza limiti la funzionalità del Web, infatti:
La piattaforma di calcolo basata su Java consiste di varie componenti:
Il linguaggio
E' principalmente caratterizzato da queste caratteristiche:
Il compilatore
Traduce i file sorgenti scritti in Java (aventi l'estensione .java)
in codice eseguibile, contenuto in uno o piu file caratterizzati
dall'estensione .class.
Sono questi i file che viaggiano sulla rete e vengono caricati
dai client Web per l'esecuzione.
I file .class hanno un formato indipendente dalla
piattaforma:
La macchina virtuale
E' il cuore di tutto il meccanismo. Essa fornisce un dispositivo
di calcolo astratto, capace di eseguire il codice contenuto nei
file .class e dotato di:
Si noti che attualmente i file .class si ottengono
a partire da codice Java, ma questo non fa parte delle specifiche
della macchina virtuale. Non è escluso che in futuro si
possano usare anche altri linguaggi sorgente (con opportuni compilatori).
Per eseguire i bytecode su una macchina reale, bisogna realizzare
un emulatore della macchina
virtuale, il cui compito è tradurre i bytecode in istruzioni
native della piattaforma HW/SW ospite.
Dunque, sono le varie implementazioni della macchina virtuale
che offrono ai bytecode l'indipendenza dalla piattaforma.
Vari modi sono possibili per implementare emulatori della macchina virtuale Java:
Nel secondo e terzo caso, la JVM è in grado di eseguire
non soltanto gli applet, ma anche applicazioni vere e proprie
scritte in Java, cioè programmi del tutto autonomi che
possono risiedere permanentemente sulla macchina ospite e possono
essere eseguiti senza utilizzare il client Web.
Tali programmi non sono soggetti alle restrizioni imposte (per
ragioni di sicurezza, come vedremo poi) agli applet.
Sono in corso di sviluppo progetti volti a realizzare un chip
che implementi la JVM direttamente in hardware, con ovvi benefici
dal punto di vista delle prestazioni.
Funzionamento nel Web
In una pagina HTML si fa riferimento a un applet con uno specifico
tag:
<APPLET CODE="game.class" WITDH=200 HEIGHT=200></APPLET>
E' possibile fornire all'applet anche ulteriori parametri, che
vengono passati all'applet al momento del lancio, quali ad esempio:
<APPLET CODE="game.class" WITDH=200 HEIGHT=200> <PARAM NAME="level" VALUE="5"> <PARAM NAME="weapons" VALUE="none"> </APPLET>
Quando il client incontra il tag Applet:
game.class;
.class che sono necessari all'esecuzione dell'applet.
Spesso, a corredo di un emulatore di JVM è consegnato un
AppletViewer, che è
un programma di supporto volto a fornire alla JVM la possibilità
di reperire attraverso il protocollo HTTP i file .class.
In sostanza, un AppletViewer può essere visto come un client
Web che sa gestire solamente il tag APPLET e ignora tutto il resto.
1.4) I problemi del Web |
Il protocollo HTTP è nato con una finalità
(lo scambio di informazioni fra gruppi di ricercatori) che si
è radicalmente modificata col passare del tempo.
Infatti, attualmente:
Questi due aspetti hanno messo alla frusta il protocollo soprattutto da tre punti di vista:
Efficienza nell'uso della rete
Il problema di fondo è che il protocollo HTTP prevede che
si apra e chiuda una connessione TCP per ogni singola coppia richiesta-risposta.
Si deve tenere presente che:
Di conseguenza, si ha che:
Assenza del concetto di sessione
In moltissime situazioni (ad esempio nelle transazioni di tipo
commerciale) è necessario ricordare lo stato dell'interazione
fra client e server, che si svolge per fasi successive.
Questo in HTTP è impossibile, per cui si devono trovare
soluzioni ad hoc (ad esempio, restituire pagine HTML dinamiche
contenenti un campo HIDDEN che identifica la transazione).
In proposito c'è una proposta (State
Management, rfc 2109) basata sull'uso dei cookies,
cioè particolari file che vengono depositati presso il
client e che servono a gestire una sorta di sessione.
Carenza di meccanismi per lo scambio di dati riservati
L'unico meccanismo esistente per il controllo degli accessi (Basic
Authentication) fa viaggiare la password dell'utente
in chiaro sulla rete, come vedremo fra breve.
HTTP versione 1.1
E' in corso di completamento la proposta, che diventerà
uno standard ufficiale di Internet, della versione 1.1 di HTTP.
Essa propone soluzioni per tutti gli aspetti problematici che abbiamo citato ed introduce ulteriori novità. I suoi aspetti salienti sono: