
5) Il livello tre (Network) |
Il livello network è incaricato di
muovere i pacchetti dalla sorgente fino alla destinazione finale,
attraversando tanti sistemi intermedi (router)
della subnet di comunicazione quanti è necessario.
Ciò è molto diverso dal compito del livello data
link, che è di muovere informazioni solo da un capo all'altro
di un singolo canale di comunicazione wire-like.
Le incombenze principali di questo livello sono:
Nel progetto e nella realizzazione del livello network di una architettura di rete si devono prendere decisioni importanti in merito a:
5.1) Servizi offerti |
In merito ai servizi offerti al livello superiore, ci sono (come abbiamo già accennato) due tipologie fondamentali di servizi:
In proposito, ci sono due scuole di pensiero:
La prima scuola di pensiero afferma che il livello network deve fornire un servizio sostanzialmente affidabile e orientato alla connessione. In questa visione, succede che:
La seconda scuola di pensiero ritiene invece che la sottorete debba solo muovere dati e nient'altro:
Di fatto, il problema è dove mettere la complessità della realizzazione:
In realtà le decisioni sono due, separate:
Le scelte più comuni sono di offrire servizi
connection oriented affidabili oppure servizi
connectionless non affidabili, mentre le altre
due combinazioni, anche se tecnicamente possibili, non sono diffuse.
5.2) Organizzazione interna della subnet |
Questo è un problema separato ed indipendente
da quello dei servizi offerti, anche se spesso c'è una
relazione fra i due.
Una subnet può essere organizzata con un funzionamento interno:
Ognuna delle due organizzazioni della subnet sopra viste ha i
suoi supporter e i suoi detrattori, anche sulla base delle seguenti
considerazioni:
|
| |
| Banda
trasmissiva |
|
|
| Spazio sui router |
| |
| Ritardo per il setup | ||
| Ritardo per il routing | ||
| Congestione |
|
|
| Vulnerabilità |
Dev'essere chiaro che i servizi offerti sono indipendenti dalla realizzazione interna della subnet. E' possibile avere tutte le quattro combinazioni di servizio offerto e implementazione della subnet:
5.3) Algoritmi di routing |
La funzione principale del livello network
è di instradare i pacchetti sulla subnet, tipicamente facendo
fare loro molti hop (letteralmente,
salti) da un router ad un altro.
Un algoritmo di routing è quella parte del software di livello network che decide su quale linea di uscita instradare un pacchetto che è arrivato:
Da un algoritmo di routing desideriamo:
Purtroppo, gli ultimi due requisiti sono spesso in conflitto fra loro; inoltre, a proposito dell'ottimalità, non sempre è chiaro cosa si voglia ottimizzare. Infatti, supponiamo che si vogliano:
Si scopre facilmente che questi due obiettivi sono in conflitto
fra loro, perché di solito aumentare il throughput allunga
le code sui router e quindi aumenta il ritardo: questo è
vero per qualunque sistema basato su code gestito in prossimità
della sua capacità massima.
Gli algoritmi di routing si dividono in due classi principali:
Gli algoritmi adattivi differiscono fra loro per:
5.3.1) Il principio di ottimalità |
E' possibile fare una considerazione generale
sull'ottimalità dei cammini, indipendentemente dallo specifico
algoritmo adottato per selezionarli.
Il principio di ottimalità
dice che se il router j è nel cammino ottimo fra i e k,
allora anche il cammino ottimo fra j e k è sulla stessa
strada:
Se così non fosse, ci sarebbe un altro cammino (ad es.
quello tratteggiato in figura) fra j e k migliore di quello che
è parte del cammino ottimo fra i e k, ma allora ci sarebbe
anche un cammino fra i e k migliore di quello ottimo.
Una diretta conseguenza è che l'insieme dei cammini ottimi
da tutti i router a uno specifico router di destinazione costituiscono
un albero, detto sink
tree per quel router.
In sostanza, gli algoritmi di routing cercano e trovano i sink
tree relativi a tutti i possibili router di destinazione, e quindi
instradano i pacchetti esclusivamente lungo tali sink tree.
5.3.2) Algoritmi statici |
Questi algoritmi, come abbiamo già
accennato, sono eseguiti solamente all'avvio della rete, e le
decisioni di routing a cui essi pervengono sono poi applicate
senza più essere modificate.
Esamineremo i seguenti algoritmi statici:
Shortest path routing
L'idea è semplice: un host di gestione della rete mantiene un grafo che rappresenta la subnet:
All'avvio della rete (o quando ci sono variazioni permanenti della topologia) l'algoritmo:
Quale sia il cammino minimo dipende da qual'è la grandezza che si vuole minimizzare. Tipicamente si usano:
Flooding
La tecnica del flooding
consiste nell'inviare ogni pacchetto su tutte le linee eccetto
quella da cui è arrivato.
In linea di principio il flooding può essere usato come
algoritmo di routing (ogni pacchetto inviato arriva a tutti i
router) ma presenta l'inconveniente di generare un numero enorme
(teoricamente infinito!) di pacchetti.
Ci sono delle tecniche per limitare il traffico generato:
Il flooding non è utilizzabile in generale come algoritmo di routing, però:
Flow-based routing
Questo algoritmo è basato sull'idea di:
Le informazioni necessarie per poter applicare l'algoritmo sono:
Vengono fatte le seguenti assunzioni:
Dai ritardi calcolati per le singole linee si può calcolare
il ritardo medio dell'intera rete, espresso come somma pesata
dei ritardi delle singole linee. Il peso di ogni linea è
dato dal traffico su quella linea diviso il traffico totale sulla
rete.
Il metodo nel suo complesso funziona così:
5.3.3) Algoritmi dinamici |
Nelle moderne reti si usano algoritmi dinamici,
che si adattano automaticamente ai cambiamenti della rete. Questi
algoritmi non sono eseguiti solo all'avvio della rete, ma rimangono
in esecuzione sui router durante il normale funzionamento della
rete.
Distance vector routing
Ogni router mantiene una tabella (vector) contenente un elemento per ogni altro router. Ogni elemento della tabella contiene:
Per i suoi vicini immediati il router stima direttamente la distanza
dei collegamenti corrispondenti, mandando speciali pacchetti
ECHO e misurando quanto tempo ci mette la risposta
a tornare.
A intervalli regolari ogni router manda la sua tabella a tutti
i vicini, e riceve quelle dei vicini.
Quando un router riceve le nuove informazioni, calcola una nuova
tabella scegliendo, fra tutte, la concatenazione migliore
per ogni destinazione.
Ovviamente, la migliore è la concatenazione che produce la minore somma di:
L'algoritmo distance vector routing funziona piuttosto bene, ma
è molto lento nel reagire alle cattive notizie, cioè
quando un collegamento va giù. Ciò è legato
al fatto che i router non conoscono la topologia della rete.
Infatti, consideriamo questo esempio:
A B C D E <- Router
*-----*-----*-----*-----* <- Collegamenti (topologia lineare)
1 2 3 4 <- Distanze da A
Se ora cade la linea fra A e B, dopo uno scambio succede questo:
A B C D E <- Router
* *-----*-----*-----* <- Collegamenti
3 2 3 4 <- Distanze da A (dopo uno scambio)
Ciò perché B, non ricevendo risposta da A, crede
di poterci arrivare via C, che ha distanza due da A. Col proseguire
degli scambi, si ha la seguente evoluzione:
A B C D E <- Router
* *-----*-----*-----* <- Collegamenti
3 4 3 4 <- Distanze da A (dopo due scambi)
5 4 5 4 <- Distanze da A (dopo tre scambi)
5 6 5 6 <- Distanze da A (dopo quattro scambi)
ecc.
A lungo andare, tutti i router vedono lentamente aumentare sempre
più la distanza per arrivare ad A. Questo è il problema
del count-to-infinity.
Se la distanza rappresenta il numero di hop si può porre
come limite il diametro della rete, ma se essa rappresenta il
ritardo l'upper bound dev'essere molto alto, altrimenti cammini
con un ritardo occasionalmente alto (magari a causa di congestione)
verrebbero considerati interrotti.
Sono state proposte molte soluzioni al problema count-to-infinity,
ma nessuna veramente efficace.
Nonostante ciò, il distance vector routing era l'algoritmo
di routing di ARPANET ed è usato anche in Internet col
nome di RIP (Routing
Internet Protocol), e nelle prime versioni di DECnet
e IPX.
Link state routing
Sopratutto a causa della lentezza di convergenza del distance
vector routing, si è cercato un approccio diverso, che
ha dato origine al link state routing.
L'idea è questa:
I passi da seguire sono:
Quando il router si avvia, invia un pacchetto
HELLO su tutte le linee in uscita. In risposta
riceve dai vicini i loro indirizzi (univoci in tutta la rete).
Inviando vari pacchetti ECHO, misurando il tempo di arrivo della
risposta (diviso 2) e mediando su vari pacchetti si deriva il
ritardo della linea.
Si costruisce un pacchetto con:
La costruzione e l'invio di tali pacchetti si verifica tipicamente:
La distribuzione dei pacchetti è la parte più delicata,
perché errori in questa fase possono portare qualche router
ad avere idee sbagliate sulla topologia, con conseguenti malfunzionamenti.
Di base si usa il flooding, inserendo nei pacchetti le coppie
(source router ID, sequence number) per eliminare i duplicati.
Tutti i pacchetti sono confermati. Inoltre, per evitare che pacchetti
vaganti (per qualche errore) girino per sempre, l'età del
pacchetto viene decrementata ogni secondo, e quando arriva a zero
il pacchetto viene scartato.
Combinando tutte le informazioni arrivate, ogni router costruisce
il grafo della subnet e calcola il cammino minimo a tutti gli
altri router.
Il link state routing è molto usato attualmente:
5.3.4) Routing gerarchico |
Quando la rete cresce fino contenere decine
di migliaia di nodi, diventa troppo gravoso mantenere in ogni
router la completa topologia. Il routing va quindi impostato in
modo gerarchico, come succede nei sistemi telefonici.
La rete viene divisa in zone (spesso dette regioni):
Di conseguenza, ci solo due livelli di routing:
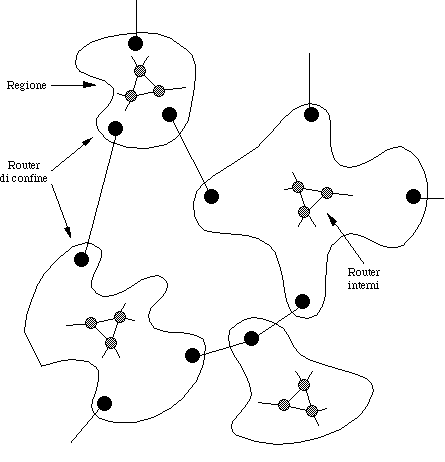
I router interni mantengono nelle loro tabelle di routing:
I router di confine, invece, mantengono:
Non è detto che due livelli siano sufficienti. In tal caso
il discorso si ripete su più livelli.