3) Il livello due (Data Link) |
Questo livello ha il compito di offrire una
comunicazione affidabile ed efficiente a due macchine adiacenti,
cioé connesse fisicamente da un canale di comunicazione
(ad es.: cavo coassiale, doppino, linea telefonica).
Esso si comporta come un "tubo digitale", cioé i bit partono e arrivano nello stesso ordine. La cosa non è banale come sembra, perché:
I protocolli usati per la comunicazione devono tenere in conto
tutto questo.
Competenze del livello data link
Questo livello ha le seguenti incombenze principali:
Servizi offerti al livello Network
Il servizio principale è trasferire dati dal livello network
della macchina di origine al livello network della macchina di
destinazione.
Come sappiamo, la trasmissione reale passa attraverso il livello
fisico, ma noi ragioniamo in termini di dialogo fra due processi
a livello data link che usano un protocollo di livello data link.
I servizi offerti possono essere diversi. I più comuni sono:
Vediamo ora un tipico esempio di funzionamento. Consideriamo un
router con alcune linee in ingresso ed alcune in uscita. Ricordiamo
che il routing avviene a livello tre (network), quindi il router
gestisce i livelli uno, due e tre.
Il livello uno accetta un flusso di bit grezzi e cerca di farli arrivare a destinazione. Però:
E' compito del livello due rilevare, e se possibile correggere, tali errori. L'approccio usuale del livello due è il seguente.
Dunque, la prima cosa (più difficile di quanto sembri)
di cui occuparsi, è come delimitare un singolo frame.
3.1) Framing |
E' rischioso usare lo spazio temporale che
intercorre tra i frame per delimitarli, perché nelle reti
in genere non ci sono garanzie di temporizzazione. Quindi, si
devono usare degli appositi marcatori per designare l'inizio e
la fine dei frame.
Ci sono vari metodi:
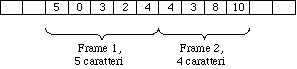
3.1.1) Conteggio |
Si utilizza un campo nell'header, per indicare
quanti caratteri ci sono del frame
Se durante la trasmissione si rovina il campo del frame che contiene
il conteggio, diventa praticamente impossibile ritrovare l'inizio
del prossimo frame e di conseguenza anche quello dei successivi.
A causa della sua scarsa affidabilità questo metodo è
usato ormai pochissimo.
3.1.2) Caratteri di inizio e fine |
Ogni frame inizia e finisce con una particolare
la sequenza di caratteri ASCII.
Una scelta diffusa è la seguente:
In questo modo, se la destinazione perde traccia dei confini di
un frame la riacquista all'arrivo della prossima coppia DLE, STX
e DLE, ETX.
Esiste però un problema: nella trasmissione di dati binari,
il byte corrispondente alla codifica di DLE può apparire
dentro il frame, imbrogliando le cose.
Per evitare questa evenienza, il livello due sorgente aggiunge
davanti a tale byte un altro DLE, per cui in arrivo solo i singoli
DLE segnano i confini dei frame. Naturalmente, il livello due
di destinazione rimuove i DLE aggiunti dentro ai dati prima di
consegnarli al livello tre. Questa tecnica si chiama character
stuffing.
3.1.3) Bit pattern di inizio e fine |
La tecnica precedente è legata alla
codifica ASCII ad 8 bit, e non va bene per codifiche più
moderne (es. UNICODE). Una tecnica analoga e più recente
permette di avere un numero qualunque di bit dentro il frame.
Ogni frame inizia e finisce con una specifica sequenza di bit
(bit pattern), ad es.:
01111110
chiamata un flag byte.
Ovviamente esiste un problema analogo al caso precedente: tale
sequenza di bit può infatti apparire all'interno dei dati
che devono essere trasmessi.
In questo caso:
Dunque, il flag byte può apparire solo all'inizio ed alla
fine dei frame. Questa tecnica va sotto il nome di
bit stuffing.
3.1.4) Violazioni della codifica |
In molte reti (sopratutto LAN) si codificano i bit al livello fisico con una certa ridondanza. Ad esempio:
Le coppie low/low ed high/high non sono utilizzate. Codifiche
come questa (Manchester encoding,
usata in IEEE 802.3) hanno lo scopo di consentire una facile determinazione
dei confini di un bit dati, poiché esso ha sempre una trasmissione
nel mezzo (però ci vuole una bandwidth doppia per trasmetterlo
a parità di velocità).
Le coppie high/high e low/low possono quindi essere usate per
delimitare i frame.
3.2) Rilevamento e correzione errori |
Ci sono molti fattori che possono provocare
errori, sopratutto sul local loop e nelle trasmissioni wireless.
Viceversa, essi sono piuttosto rari nei mezzi più moderni
quali le fibre ottiche.
Gli errori sono dovuti in generale a:
Ci sono due approcci al trattamento degli errori:
3.2.1) Codici per la correzione degli errori |
Normalmente, un frame (a parte i delimitatori)
consiste di
bit, dove:
Una sequenza di n bit fatta in tal modo si dice codeword,
o parola di codice.
Date due qualunque parole di codice, ad es.:
1000 1001
1011 0001
è possibile determinare il numero di bit che in esse differiscono
(tre nell'esempio) tramite un semplice XOR fatto bit a bit.
Tale numero si dice la distanza di Hamming
delle due codeword (Hamming, 1956). Se due codeword hanno una
distanza di Hamming uguale a d, ci vogliono esattamente d errori
su singoli bit per trasformare l'una nell'altra.
Un insieme prefissato di codeword costituisce un codice
(code). La distanza
di Hamming di un codice è il minimo delle
distanze di Hamming fra tutte le possibili coppie di codeword
del codice.
Ora, le capacità di rilevare o correggere gli errori dipendono
strettamente dalla distanza di Hamming del codice scelto.
In particolare:
Dunque, a seconda degli scopi che si vogliono raggiungere, si
progetta un algoritmo per il calcolo degli r check bit (in funzione
degli m bit del messaggio) in modo che i codeword di n = m + r
bit risultanti costituiscano un codice con la desiderata distanza
di Hamming.
Vediamo ora, come esempio, un codice ottenuto mediante l'aggiunta
di un bit di parità, calcolato in modo tale che il numero
totale di bit uguali ad 1 sia pari (in questo caso si parla di
even parity)
<-- m --> r
1011 0101 1
1000 0111 0
Questo codice, detto codice di parità
(parity code) ha distanza
di Hamming uguale a due, e dunque è in grado di rilevare
singoli errori. Infatti, un singolo errore produce un numero dispari
di 1 e quindi un codeword non valido.
Come secondo esempio, consideriamo il codice costituito dalle
seguenti codeword:
00000 00000
00000 11111
11111 00000
11111 11111
Esso ha distanza 5, per cui corregge due errori (cifre sottolineate).
Infatti, se arriva
00000 001111
si può risalire correttamente al codeword più vicino,
che è
00000 11111
Però, se ci sono tre errori ed arriva
00000 00111
siamo nei guai, perché esso verrà intrepretato erroneamente
come
00000 11111
anziché come
00000 00000
Per correggere un singolo errore su m bit, si devono impiegare
almeno r check bit, con
ossia sono necessari circa lg2 m bit. Esiste un codice
(codice di Hamming) che
raggiunge questo limite teorico.
Ora, c'è una semplice tecnica con la quale tale codice
può essere impiegato per correggere gruppi contigui di
errori (detti burst di errori)
di lunghezza massima prefissata.
Supponiamo di voler correggere burst di lunghezza k:
3.2.2) Codici per il rilevamento degli errori |
I codici correttori di errore sono usati raramente
(ad esempio in presenza di trasmissioni simplex, nelle quali non
è possibile inviare al mittente una richiesta di ritrasmissione),
perché in generale è più efficiente limitarsi
a rilevare gli errori e ritrasmettere saltuariamente i dati piuttosto
che impiegare un codice (più dispendioso in termini di
ridondanza) per la correzione degli errori.
Infatti, ad esempio, supponiamo di avere:
Per correggere errori singoli su un blocco di 1.000 bit, ci vogliono
10 bit, per cui un Megabit richiede 10.000 check bit.
Viceversa, per rilevare l'errore in un blocco, basta un bit (con
parity code). Ora, con 10-6 di tasso d'errore, solo
un blocco su 1.000 è sbagliato e quindi deve essere ritrasmesso.
Di conseguenza, per ogni Megabit si devono rispedire 1.001 bit
(un blocco più il parity bit).
Dunque, l'overhead totale su un Megabit è:
L'uso del parity bit può servire (con un meccanismo analogo
a quello visto per la correzione di burst di k errori) per rilevare
burst di errori di lunghezza <= k. La differenza è che
non si usano r check bit per ogni codeword, ma uno solo.
Esiste però un altro metodo che nella pratica viene usato quasi sempre, il Cyclic Redundancy Code (CRC), noto anche come polynomial code. I polynomial code sono basati sull'idea di considerare le stringhe di bit come rappresentazioni di polinomi a coefficenti 0 e 1 (un numero ad m bit corrisponde ad un polinomio di grado m-1).
Ad sempio, la stringa di bit 1101 corrisponde al polinomio x3
+ x2 + x0.
L'aritmetica polinomiale è fatta modulo 2, secondo le regole della teoria algebrica dei campi. In particolare:
Il mittente ed il destinatario si mettono d'accordo su un polinomio
generatore G(x), che deve avere il bit più significativo
e quello meno significativo entrambi uguali ad 1. Supponiamo che
G(x) abbia r bit.
Il frame M(x), del quale si vuole calcolare il checksum, dev'essere
più lungo di G(x). Supponiamo che abbia m bit, con m >
r.
L'idea è di appendere in coda al frame un checksum tale
che il polinomio corrispondente (che ha grado m + r -1) sia divisibile
per G(x).
Quando il ricevitore riceve il frame più il checksum, divide
il tutto per G(x). Se il risultato è zero è tutto
OK, altrimenti c'è stato un errore.
Il calcolo del checksum si effettua come segue:
Questo metodo è molto potente, infatti un codice polinomiale con r bit:
Tra i polinomi sono diventati standard internazionali:
Un checksum a 16 bit corregge:
Questi risultati valgono sotto l'ipotesi che gli m bit del messagio
siano distribuiti casualmente, il che però non è
vero nella realtà, per cui i burst di 17 e 18 possono sfuggire
più spesso di quanto si creda.